
Code-as-Room brings diverse interactive 3D scenes from a single top-down view image. We design an agentic system with a structured execution harness and activate the MLLMs' ability to understand, design, and code the 3D rooms in Blender.
Abstract
Designing realistic and functional 3D indoor rooms is essential for a wide range of applications, including interior design, virtual reality, gaming, and embodied AI. While recent MLLM-based approaches have shown great potential for 3D room synthesis from textual descriptions or reference images, text-based methods struggle to capture precise spatial information, and existing image-conditioned agents suffer from instability and infinite looping when tasked with holistic room generation from top-down views. To address these limitations, we propose Code-as-Room, an MLLM-based agentic framework equipped with a structured execution harness, which represents 3D rooms with Blender codes. Given a top-down room image, the framework parses the reference image to extract scene elements and their spatial relationships, and synthesizes executable Blender code for geometry, materials, and lighting in a principled, multi-stage pipeline. A cross-stage memory module is maintained throughout to mitigate context forgetting inherent to existing agent-based frameworks. We further introduce a dedicated benchmark for code-based 3D room synthesis, encompassing various evaluation protocols. Based on our benchmark, comprehensive comparisons against existing agent-based methods are conducted to validate the effectiveness of our proposed execution harness.
Method Overview
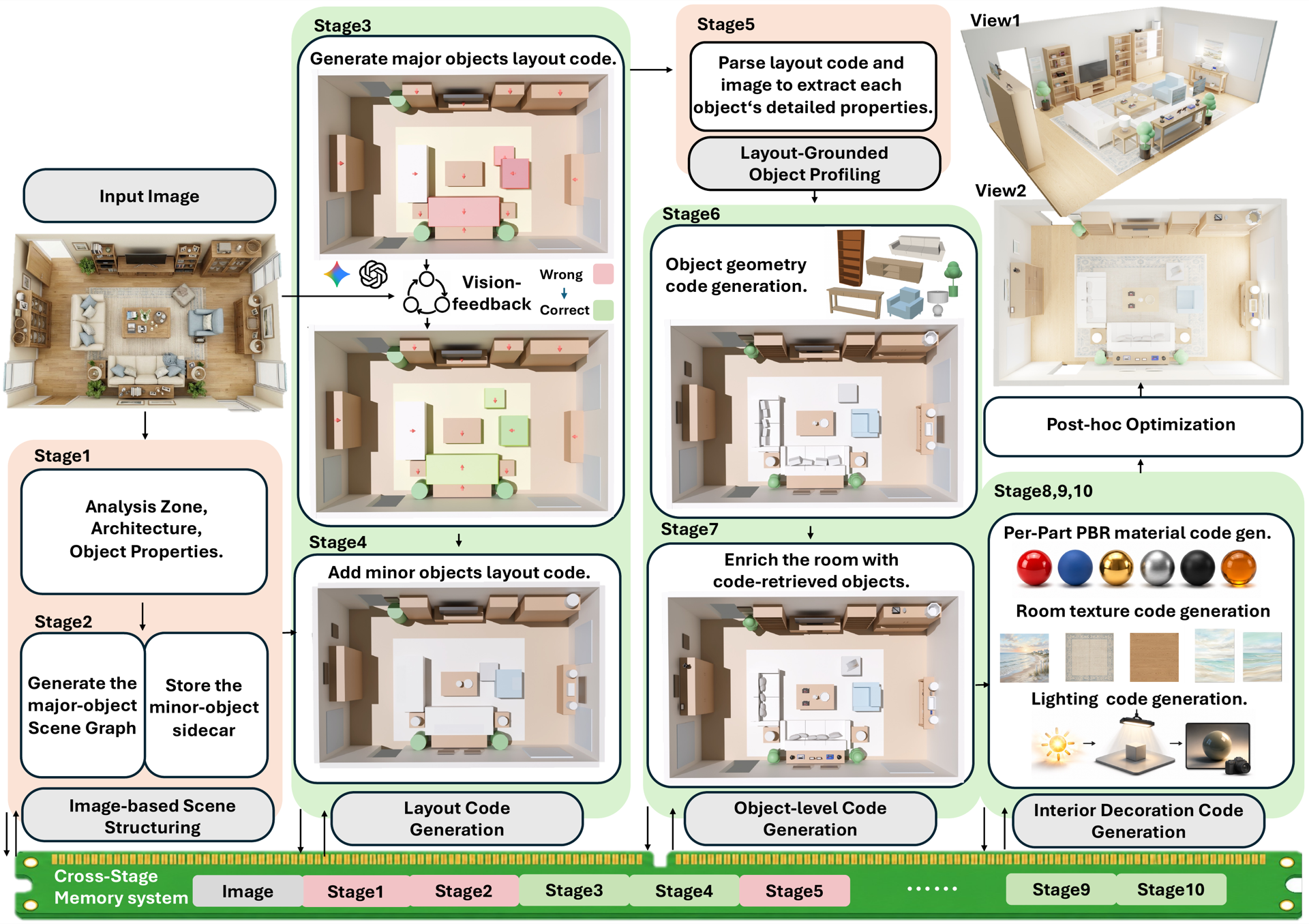
Overview of the Code-as-Room pipeline. A single top-down view image is progressively transformed into a fully renderable 3D scene through a sequence of specialized MLLM agent stages, organized into five phases: image-based scene structuring, layout code generation, layout-grounded object profiling, object-level code generation, and interior decoration code generation. Arrows denote data flow through the cross-stage memory system, wherein each stage reads upstream outputs and writes its own results as typed memory entries.
Video Demo
Turntable Comparisons with VIGA
Comparison of our method with VIGA baseline on different scenes:



Model Comparisons on Benchmark
Turntable videos comparing different MLLM models (GPT-5.5, Gemini 3.1, Gemini 3 Flash) on various difficulty levels:



More Results
Walkthrough Videos
Qualitative Results


Comparison with Baselines

Re-rendering Results

Citation
@article{yang2026codeasroom,
title={Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis},
author={Yang, Yixuan and Luo, Zhen and Gan, Wanshui and Hao, Jinkun and Lu, Junru and Yan, Jinghao and Lyu, Zhaoyang and Xu, Xudong},
journal={arXiv preprint arXiv:2605.18451},
year={2026}
}